
At some point in the last year, I referred a coworker to xkcd 1205 simply by number. Like it was RFC 1918 or Apollo 13 or Louis XIV. That's the one where Randall maps out the is-it-worth-it calculation for automating a task. This one:

It's a much better reference than my handy graph at the top of this post, easier to find and more credible, so I use it a lot. Enough to remember it by number.
We[1] typically think about automation opportunities as a hunt for activities that are "above the line," whose frequency and cost are high enough to warrant spending the time to automate them away, and we push the time-per-task point down to reclaim inefficiencies, or sometimes to the left to eliminate low-value work.

If part of your job is making data-driven decisions, or if depends on influencing someone who does, you've probably experienced something akin to the following dance:
{technologists, engineers, nerds}↩︎
Person 2: That's an oddly specific number! I bet it's not exactly $1M, what factors did you use to estimate cost?
P1: It's 4 teams of 10 people for 250 hours each, at $100/hr.
P2: I see. Those feel like good, round numbers to start with. Do you have a best- and worst-case scenario?
P1: We could do it with 3 teams of 8 if we're lucky, but we're also dependent on a couple things falling into place, so it could be as high as 500 hours if the work is more complex than we thought.
P2: so your 90% confidence interval is actually more like $0.6M to $2M? Let's use that range and talk further.
The reason this blog is about getguesstimate.com is that it pulls off something quite remarkable: it takes one particularly interesting and useful activity -- building a Monte Carlo simulation -- and turns it from a painfully difficult task to one that's easy enough that it invites more frequent use. It inverted the paradigm of xkcd 1205 from "how can I automate this task away" to "how much more often would I derive high utility from this if it were well-automated?" It magically shifts the graph down and to the right!

My first exposure to Monte Carlo models was leading the team building Annual Loss Expectancy estimates for catastrophic security breach events. We had a brilliant CIO and a fastidious CFO. Together, they made for a formidable committee that was going to pressure-test my team's recommendation strategy for our annual cybersecurity insurance renewal. The conversation went something like:
CIO and CFO, in unison: Do y'all have a model of your own or are we just taking the brokers' word for it? You know... the brokers... who are selling us the insurance?
An intrepid teammate raised their hand and said, "I've been wanting to learn to do this, I'll build the model." A month later, we had one![1] And we also had a y-coordinate for the "building a MC" point on our information risk team's utility graph.
My next exposure to Monte Carlo modeling was in reading Doug Hubbard's How To Measure Anything in Cybersecurity Risk.[2] One of the download companions to HTMA[3] is a model built in Excel. I was excited to have something I could experiment with and adapt without imposing on my team. It looked like this:[4]

It was complicated and a little bit fragile.[5] I was intimidated, and I was undeterred. I learned to build models in Excel, because I knew I'd someday need them again. I had moved the point on the graph down from a month to a week.
I don't remember exactly when I stumbled across getguesstimate.com. I do remember playing with it and finding it so simple that I briefly doubted its veracity. So I tested it against a model I knew would be right: Hubbard's. I took the inputs and ranges, set up the math, and let the model run... by which I mean I did nothing and checked my results in the browser.

The shape of the graph, the bracketing of the 90% confidence interval, the break-even estimation, the most-likely outcome... all matched to within a few percentage points. And I had moved the point on my xkcd-1205 graph down from days to... well... minutes, with a little bit of practice. Success![6]
Having gotten familiar enough with getguesstimate to use it casually, I wanted to get back to the cyberinsurance model that we'd built. That was a sophisticated use case and would allow me to try some of the features of the tool out "in anger".[7]
The first step was to figure out how to fine-tune distributions within ranges. getguesstimate has three built-in defaults: a lognormal distribution[8], a normal distribution, and a uniform (flat) distribution:

Sources I trust a lot[9] recommend PERT as a simple, reliable distribution when modeling work knowing the most-likely (mode), pessimistic (min), and optimistic (max) characteristics of a task. getguesstimate handled this beautifully.

As a CISO and a motivated, hands-on user, one of my frustrations with FAIR was how complicated it was to enter data into their UI's. It took dozens of clicks and a lot of scrolling to complete the basic elements of a single scenario.

I was very excited about getguesstimate's option to have a fits-on-a-single-page-with-room-to-spare calculator that solicited all the inputs I needed with a simple link and very little clicking around. For democratizing the gathering of expert inputs, this is a game-changer.

The upshot: in the span of several hours[10], I was able to construct both the FAIR modeler and a simple ALE monte carlo that rivaled our presentation to the CIO and CFO. Unlike our Excel-based model, getguesstimate allowed me to be both repeatable and fast. And that's a game-changer!
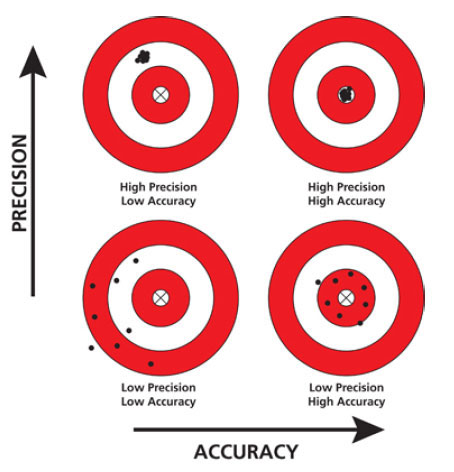
Coda (or pics-or-it-didn't-happen): The best thing I can say about getguesstimate is that it makes me a better source for expertise. I avoid the trap of substituting precision for accuracy[11] when I'm giving advice, confidently, without sacrificing days or weeks of clock time to get there.

To my friend hiring those consultants... good luck, you're welcome, and most of all thank Ozzie and the team over at getguesstimate, they're pretty great!
I'm so glad I asked early in the process -- thank you @GP for the intrepid volunteerism, you came through in the clutch ↩︎
after reading the original HTMA and questioning how that much calculus could ever translate to an audiobook, an option I considered and passed on ↩︎
imagine 10,000 more rows... literally, because #montecarlothings ↩︎
I learned quickly just what key presses would or would NOT cause Excel to re-run
NORMINV(RAND())ten thousand times ↩︎if you're interested in playing with that model, you can find it here ↩︎
Robin Kelland, I'm not sure where you are nowadays, I do hope you picked up at least one catch phrase from me so we can call it an even exchange ↩︎
with the mode and median left-of-center ↩︎
and after a reasonable amount of time spent learning the tool -- between 10 and 25 feels like a safe range ↩︎
since most people, myself included, are terrible when attempting to do anything, regularly, with high precision
 ↩︎
↩︎
